- 컴퓨텍스 2016에서 ARM의 신규 CPU 아키텍처, Cortex-A73이 발표되었습니다.
그 동안 코드네임 아르테미스(Artemis)로 알려진 아키텍처입니다.
(링크 : http://pc.watch.impress.co.jp/docs/column/kaigai/759881.html)
(링크 : http://www.anandtech.com/show/10347/arm-cortex-a73-artemis-unveiled)
- 개요

성능, 전력 효율이 올라간다는 내용인데 당연한 얘기입니다.
동일 클럭에서 성능 비교를 보면 A72 -> A73 이 +5% 정도로 표기되어있습니다.
A72 -> A73 성능 상승치는 +13%로 나옵니다.
(성능축은 1부터가 아니라 0부터 봐야합니다.)
다른 내용으로 봤을 때, A72는 16nm, A73은 10nm 일겁니다.

16nm A72 대비 10nm A73은
최대 2.8GHz, 성능 +30%
전력 효율 +30%
1코어 면적 0.65mm2

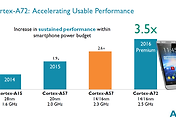
최대 성능과 (일정 TDP 내에서) 유지 가능한 성능의 비교입니다.
기존과 달리 피크 성능과 유지 성능간 차이가 거의 없다는 내용.
그래프를 비례관계로 보면,
|
Spec2K |
20nm A57 |
16nm A72 |
10nm A73 |
|
최대 성능(Ratio) |
0.68 |
1.00 |
1.12 |
|
유지 성능(Ratio) |
0.60 |
1.00 |
1.29 |
|
최대 클럭(GHz) |
1.9 |
2.5 |
2.8 |
|
유지 클럭(GHz) |
1.41 |
2.11 |
2.74 |
|
클럭당 성능(Ratio) |
0.89 |
1.00 |
1.00 |
Spec2k에서 A73의 동클럭성능이 A72와 같은 수준이라는 결과가 나옵니다.
이는 동클럭 성능 차이가 5% 정도로 나왔던 첫번째 자료와 맞지 않는 내용입니다.
ARM이 표기한 x1.3, x2.1 이라는 성능 차이나 기존에 Specint2K에서 A57-A72의 동클럭성능 차이가 11% 내외였던 점이 차트와 일치하는걸 봤을 때, Spec2k는 정확히는 Specint 2K로 보이고 A73의 동클럭성능이 A72와 같은 수준이라는 내용을 부정하기는 어려워 보입니다.
동클럭 성능은 같지만 전력효율을 개선하여 실사용시 성능(=유지 가능한 성능)을 높였다라는걸 어필하고 싶은듯 합니다.
첫번째 자료에서 동클럭 성능 향상이 +5% 정도로 나왔고, 최대 성능 +13%이니 최대 클럭은 +8%로 계산됩니다. Spec2K 기준 자료에서 최대 성능차이, 최대 클럭 둘 다 +12% 였고요.
첫번째 자료는 Spec2K 기준이 아닐 가능성도 있어 보입니다.
그런데 Spec2K 기준으로 안 보자니 Performance/cycle 이란 표현을 쓴다는게 문제입니다.
이건 차트의 기준이 되는 벤치마크가 CPU 클럭에 비례하는 결과를 보여준다는걸 의미합니다.
긱벤치처럼 메모리 점수가 반영되어서 총점이 CPU 클럭에 비례하지 않는, 그런 벤치마크가 기준이 아니라는거지요.
그렇다면 대체 어떤 벤치마크 기준이냐하는게 의문인데 ARM의 전례를 봤을 때는 Specint 외에 딱히 꼽을만한게 없습니다.
Specint2K라면 앞뒤가 안 맞는데 추가 정보를 기다려봐야겠습니다.

각 조건에서 성능 향상치인데 딱히 계산해볼 수 있는 툴을 쓴게 아니네요.

정수, 부동소수점, 메모리 전력 효율 비교.
+20% 이상 좋아졌다고 하네요.

프리미엄 CPU(빅코어 아키텍처) 면적 감소를 보여줍니다.
16nm A72 대비 -46%
기본적으로 효율적인 설계가 뒷받침되어야겠지만 공정 미세화의 영향도 따져봐야 합니다.
(뒤에서 다루겠지만) 공정이 각각 TSMC 16FF+ , 10FF로 보이는데,
TSMC 16nm 공정은 백엔드가 20nm와 같아서 최종적인 면적은 20nm와 차이가 없는 것으로 알려져 있습니다.
위 슬라이드의 값으로 계산해보면, 면적비는 20nm A57 : 16nm A72 : 10nm A73 = 1 : 0.56 : 0.3 입니다.
공정상 면적 감소가 거의 없는 20nm -> 16nm 에서 면적이 44%나 줄은건 확실히 설계의 힘이겠지요.
하지만 16nm -> 10nm는 얘기가 다릅니다.
TSMC의 경우 EUV를 쓴다는 얘기까지 나왔으니 면적 감소는 확실한 상황이고 얼마나 줄어들지가 불확실한 상황일뿐입니다.
삼성의 경우, 20nm -> 14nm 에서 면적 -15% 정도로 알려져 있고, 최근 풀노드 공정미세화에서 면적감소치가 -30% 정도인 점을 감안하면, 삼성의 면적 감소는 20nm -> 10nm에서 -40% 정도로 계산해볼 수 있습니다.
TSMC가 이 차이를 따라잡는다고 가정하면 TSMC 16nm -> 10nm 면적 감소치는 -40% 내외로 볼 수 있습니다.
그런 차원에서 본다면 16nm A72 -> 10nm A73에서 면적 -46%는 그렇게 큰 값이 아닙니다.
단순 계산으로 보면 면적감소에서 설계에 의한 비중은 10%정도가 됩니다.

10FF 같은 최신 공정은 물론, 28HPC같은 중저가형을 위한 공정에서도 쓸 수 있는 아키텍처라는 내용.
하지만 A72 사례에서 알 수 있듯이 최신 빅코어 아키텍처를 (상대적으로) 구형 공정에서 쓰는건 라인업 구성, 원가 등 현실적 제약때문에 쉽지 않아 보입니다.

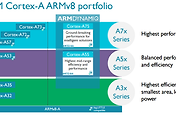
진화하고 있는 빅리틀.
기존에 빅리틀은 단순히 마이그레이션, MP 정도로 알려있었지만 IPA, EAS 같은 것들이 추가되고 있습니다.
IPA는 이미 커널 등에서 보이고 있는 방식으로 간단히 말하면 기존 방식에 발열관리가 추가된 개념으로 보면 될듯 합니다.
빅코어 로드맵에서 A73이 2016년에 배치된걸 기억할 필요가 있습니다. (뒤에서 다룰겁니다.)
- 아키텍처


(원래 구구절절 있는 얘기 다 쓰려고 했는데 그냥 다 생략하겠습니다.)
A72와 비교해서 간략히 보면
명령 디코더는 3명령/cycle에서 2명령/cycle로 축소.(3 Macro-OPs)
최대 6 Micro-OP 발행. (FP 2 OPs 포함)
파이프라인 최대 15 stage에서 11 stage로 감소.
수치적인 사양은 내려간듯 하지만 분기예측, prefetch, 메모리 액세스 등에서 개선이 이루어져서 성능이 올라갔습니다.
Cortex-A9가 2명령/cycle decode 구조인걸 생각하면 그동안 엄청나게 개량이 되었다는걸 알 수 있지요.
사실 A72 -> A73은 A15 -> A17에서의 변화와 유사해서, A15 -> A17 과 같은 방식의 개량이 A57 -> A73에서도 이루어졌다라고 보는 시각과, A15 -> A57, A17 -> A73 의 병렬적인 아키텍처 라인업이라고 보는 시각이 가능합니다.
개인적으로 후자 쪽이 더 적당하지 않을까 싶네요. (개발팀이 다르기도 하고요.)
- 테스트 칩
테스트 칩 테스트 결과입니다.
(링크 : http://www.pcper.com/reviews/Processors/ARM-Produces-10nm-Artemis-Test-Chip)

A73 쿼드에 Mali GPU 1코어 구성입니다.
TSMC 10FF 공정으로 15년 12월 테이프 아웃, 16년 4/5월에 나왔다고 하네요.


10FF A73 - 16FFLL A72(저전력 구성이라고 생각하면 됩니다.)를 비교하면
동일 전력에서 성능 +11~12%
동일 성능에서 전력 -30%
전력 기준이 dymanic power, leakage power를 포함했기때문에 +11~12%가 speed gain값이라고 확정하기는 어려울듯 합니다.
게다가 아래에 있듯이 PDK v0.5인걸 보면 A73이 아직 10FF 공정에 최적화되어있지 않을 가능성도 있습니다.
아키텍처도 달라서 이 데이터로 10FF 공정 성능을 평가하기는 어렵다고 봅니다.
아래 표를 보면 A73 클럭이 오히려 낮습니다.
성능 향상치는 클럭 향상치가 아니라 어떤 툴을 활용한 테스트 결과를 비교한 것이라고 봐야합니다.

클럭을 보면 A73이 10% 정도 낮은데 성능은 오히려 10% 정도 높게 나왔다는 얘기가 됩니다.
동클럭 성능으로 보면 +20% 내외가 됩니다.
이 역시 성능 기준을 알 수 없으니 뭔가 결론을 내기 힘듭니다.
- 로드맵
앞서 A73이 2016년으로 표기된 내용이 있었습니다.
이걸 기존에 나왔던 로드맵과 비교해 보겠습니다.

시간축을 보면 2014년까지만 표기되어 있습니다.
Cortex-A72가 나와 있는데 2015년 2월에 발표되었고, 당시 발표에서 16FF+에서 최대 클럭은 2.53GHz라고 했습니다.
위 로드맵과 잘 안 맞다고 봐야겠지요.
2015년 이전, 2014년에 나온 로드맵일 가능성이 높습니다.
또 다른 부분은 아르테미스 외에 다른 아키텍처로 프로메테우스, 아레스가 나와있습니다.
아르테미스 타겟 공정은 16FF, 프로메테우스 타겟 공정은 10FF 입니다.
아르테미스는 라인업상 최상위 코어도 아닙니다.
플래그쉽급이 아닌 하이엔드-미드레인지급 코어로 취급되고 있는거지요.

이건 그 이후에 나온 로드맵입니다.
프로메테우스, 아레스는 빠지고 아르테미스만 표기되어 있습니다.
이 두 건을 종합하면 아르테미스는 본래 최상위 코어로 계획되지 않았습니다.
타겟 공정이 최상위 공정이 아닌(심지어 16FF+도 아니고 16FF 입니다.) 하이엔드-미드레인지급 코어였고, 그러기위해서는 성능보다는 전력 효율을 중시하는 타입이었을 가능성이 높습니다.
A57 - 아르테미스 - 프로메테우스 - 아레스 순의 로드맵을 생각해 볼 수 있습니다.
아르테미스는 로드맵에서 A72의 후속이 아닌 A57의 후속으로 나와있는걸 봐서는 A57과 비슷한 성능에 전력효율을 높인 형태였을 가능성이 있습니다.
최종적으로 A73이 나온 형태는 전력효율이 개선되고, 성능은 A57 대비 A72 수준으로 올라간게 되는데 이건 초기 로드맵으로 보면 아르테미스와 프로메테우스의 중간 형태가 됩니다.
아레스는 전력범위 자체가 다르니 넘어가고, 아르테미스와 프로메테우스만 보면 A73에 대한 포지셔닝은 두 가지 경우로 볼 수 있습니다.
기존 아르테미스와 프로메테우스를 통합한 형태로 로드맵상 프로메테우스는 삭제되는 경우.
혹은 아르테미스가 로드맵상 상향되고, 그에 따라 프로메테우스도 상향되는 경우.
어느 쪽일지는 시간이 지나봐야 알겠지요.
'스마트폰 > ARM Holdings' 카테고리의 다른 글
| ARM Cortex-A75/A55, Mali-G72 발표. (24) | 2017.06.06 |
|---|---|
| Cortex-A73 긱벤치4 성능. (화웨이 기린960) (update 2016.12.04.) (12) | 2016.11.11 |
| ARM Cortex-A72 세부정보 공개. (Update 2015.05.30) (43) | 2015.05.30 |
| Cortex-A72 성능, 전력 자료. (source : 화웨이) (33) | 2015.04.20 |
| Cortex-A72 긱벤치 성능 추정. (Geekbench3) (update 2015.04.11) (11) | 2015.04.11 |

댓글