- ARM에서 Cortex-A72의 상세 정보를 공개했습니다.
엠바고가 걸려있었나 봅니다.
- 변경 내용을 하나하나 뜯어보는건 별 의미가 없어보입니다.
그래서 실제 성능이 어떻게 나오느냐가 중요한거니까요.


분기예측(Branch Prediction)이 Cortex-A72의 가장 중요한 확장 포인트.
BTB(Branch Prediction Buffer)는 가까운 범위로 분기하는 small branch에 대해 최적화.
Large branch에 대해 BTB 크기는 2000개를 store 할 수 있지만, Small branch에서는 BTB를 분할하여 4000개 store
현실적으로 많은 분기가 small branch이기때문이라고.
분기예측 알고리즘 개선 : misprediction 50% 감소, speculation 25% 감소.
* prediction : 분기 방향, 목적지를 예측.
* speculation : 분기 결과를 예측.
메모리 전력 최적화.
분기명령이 없는 분기 윈도우를 사전에 감지. 큰 basic block 내의 16B에서 분기예측기능을 off
-> 전력 낭비 감소.
(기존에는 전체 윈도우마다 예측 기능을 실행.)

디코더/리네임 스테이지에서 루프 버퍼(Lopp Buffer) 제거.
* 루프 버퍼 : 디코딩 된 uOPs(micro-ops)를 캐시. 루프로 같은 명령을 반복할 경우 캐시된 uOPs를 읽어냄.
A57에는 32 엔트리의 루프 버퍼가 있었으나 A72에서는 매우 작은 용량의 버퍼만 남기고 삭제.
전력 효율성 측면에서 유용하지 않았다고.

명령 dispatch 증가 : 최대 3 -> 5 uOPs, 파이프라인 가동효율 증가.
기존 A57
디코더 최대 3 uOPs 발행 -> 디스패치(Dispatch) 유닛 최대 3 uOPs dispatch 발행
-> 큐(Queue) 최대 3 uOPs/cycle
A72
디코더 최대 3 macro-ops 발행 (최대 5 uOPs 발행, 여려개의 uOPs를 묶어 macro-ops 발행)
-> 디스패치(Dispatch) 유닛 최대 3 macro-ops 발행 -> 큐(Queue) 최대 5 uOPs/cycle
macro-ops 디코드 비율은 8% 정도.
기존 대비 8% 더 많은 micro-ops가 처리된다는거. (성능향상이 10% 정도인건 이 때문?)

FP/SIMD 파이프라인 레이턴시 감소.
FMUL : 5 -> 3 사이클.
FADD : 4 -> 3 사이클.
FMAC : 9 -> 6 사이클.
파이프라인 최대 19 stage에서 16 stage로 감소.



- 성능

3.5배라던 대책없는 내용도 보강이 되었습니다.
클럭 표시까지는 해줬네요.
A57이 14nm에서는 2.3GHz까지 가능한가봅니다.
여전히 2.6배, 3.5배 하는 수치는 믿기가 힘듭니다.

총 에너지 소비량 자료도 보강되었습니다.
성능에서 A15 1.6GHz = A57 1.3GHz = A72 1.1GHz 라고 합니다.
그러면 A72는 A57 대비 클럭당성능이 +18% 라는 얘기가 됩니다.
A57은 A15 대비 클럭당성능 +23%
동일 노드에서 A72는 A57 대비 -22% 로 그래프에는 나오는데,
화웨이 자료로 A57 1.3GHz, A72 1.1GHz 전력을 비교해보면 A72가 A57 대비 -30% 정도로 나옵니다.
(링크 : Cortex-A72 성능, 전력 자료. (source : 화웨이))
얼추맞다고 봐도 될듯 합니다.
그리고 이 그래프대로라면 동클럭 전력은
28nm -> 20nm : -12.5%
28nm -> 16FF+ : -50%
20nm -> 16FF+ : -43%
TSMC 16nm 공정이 언제 양산될지도 모르는 상황이라 현재로는 믿거나 말거나 참고사항.

동클럭 성능 비교.
SPEC2006, 긱벤치 등등이 종합된거라 구체적으로 따질거리가 없습니다.

인텔 제온과의 비교입니다.
1/3의 전력으로 제온과 같은 성능을 낼 수 있다는건데, 굳이 이런 얘기까지 나오는거보니 서버쪽을 노리나 봅니다.

인텔 코어M과의 비교입니다. (A72 2.5GHz 예상치)
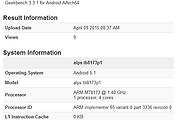
긱벤치 결과는 아마 맞긴할겁니다.
현재 올라온 A72 2.0GHz 결과로 보건데 2.5GHz라면 코어M과 싱글스레드에서는 비슷한 결과가 나올겁니다.
코어M이 2코어4스레드이고, A72는 4코어로 잡았으니 당연히 멀티스레드는 A72가 높겠지요.
그런데 어차피 긱벤치에서 X86 점수가 그렇게 잘 나온다고 보기 힘들기때문에 이걸 동등한 비교로 보기는 힘듭니다.
(개인적으로는 X86과 ARM을 긱벤치로 비교할거면 X86 점수를 두 배로 놓고해야 어느정도 동등해진다고 봄.)
그래도 주목되는건 SPECint/fp 결과.
아무리 코어M이라도 싱글스레드에서는 비교적 쓰로틀링에서 자유로울텐데 그 상태에서 A72가 80% 수준으로 나옵니다.
클럭이 20% 높은데 성능이 80% 수준이라면 A72의 클럭당성능이 코어M의 64% 수준이라는게 됩니다.
컴파일러 최적화의 영향이 있기때문에 구체적인 수치에 대해서는 논란의 여지는 있습니다만, ARM이 X86 많이 따라왔다는데는 이견이 없을듯 합니다.
싱글스레드에서 A72가 1W 미만이라고 하는데, 이건 ARM이 코어 설계시 코어당 소비전력을 600~750mW 선으로 잡기때문에 나온 얘기인듯 합니다.
실제로는 다른 부분까지 다 포함해서 1W는 가볍게 넘어갑니다.
- update 2015.05.30
http://pc.watch.impress.co.jp/docs/column/kaigai/20150529_704264.html
'스마트폰 > ARM Holdings' 카테고리의 다른 글
| Cortex-A73 긱벤치4 성능. (화웨이 기린960) (update 2016.12.04.) (12) | 2016.11.11 |
|---|---|
| ARM Cortex-A73 발표. (코드네임 : 아르테미스, Artemis) (24) | 2016.06.03 |
| Cortex-A72 성능, 전력 자료. (source : 화웨이) (33) | 2015.04.20 |
| Cortex-A72 긱벤치 성능 추정. (Geekbench3) (update 2015.04.11) (11) | 2015.04.11 |
| ARM Mali-T760/T628 MP별 Performance scaling (12) | 2015.03.29 |



댓글