- Renesas Salvator-X 라는 이름으로 GFX벤치에 올라와서 이것저것 찾아봤습니다.
R-Car H3은 이름에서 보이듯이 차량용 SoC입니다.
오토모티브 인포메이션 컴퓨팅 플랫폼이라고 하는데 차량용 인포메이션 시스템용 정도로 생각하면 되겠지요.
구체적인 용도까지는 더 알아보시길.
저는 사양만 볼겁니다.
Salvator-X는 개발 보드 이름같은데 '구세주'라고 이름붙인게 너무 거창한거 아닌가 싶기도 한데, 차량용인걸 생각하면 어울리는거 같기도 하고. (저 단어에 다른 뜻이 있는걸지도.)


SiP 구성.

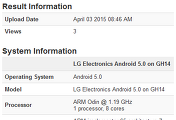
- CPU, 램 : 시스템 정보

시스템 정보를 보면
Cortex-A57 쿼드코어.
이매지네이션 PowerVR GX6650
API가 OpneGL ES 3.2 적용인게 특이합니다. 왠만한 모바일용 AP보다 지원이 좋네요.

블록 다이어그램을 보면 Cortex-A57 x4 + Cortex-A53 x4 + Cortex-R7 x2 구성입니다.
르네사스에서는 이걸로 10코어 구성이라고 했습니다.
램은 LPDDR4-3200, 32bit x4


발표 사양은 Cortex-A57 쿼드 2.0GHz + Cortex-A53 쿼드 1.2GHz + Cortex-R7 x2 800MHz,
GX6650 700MHz
16nm 공정이라는데 TSMC 16FF 인지 16FF+ 인지 불명.
르네사스 발표 성능을 보면 CPU 성능은 40,000 DMIPS
10코어 구성인데 GFX벤치 시스템 정보에는 4코어로 나옵니다.
Cortex-R7 을 빼고 생각한다해도 8코어 구성이 4코어로 표기된다는건 HMP가 아닌 클러스터 마이그레이션이나 IKS 이라는게 됩니다.
40,000 DMIPS, 발표 사양으로 역산하면 Cortex-A57은 5.0 DMIPS/MHz, 쿼드코어 2.0GHz 사양.
숫자는 들어맞습니다.
단순 계산으로도 A53의 성능만 2.3 DMIPS/MHz x4코어 x1200MHZ = 11040 DMIPS
만약 A53 성능까지 포함했다면 A57의 1/4이나 되는 A53 성능이 빠졌을리가 없습니다.

비교군인 R-Car H2의 성능이 25,000 DMIPS로 표기된 점을 생각하면 쿼드코어라는 시스템 표기가 최종적인게 아니라고 생각할 수 있는 가능성을 만듭니다. (아마 쿼드코어가 맞겠지만요.)
25,000 DMIPS로 역산하면 Cortex-A15 1.8GHz 쿼드코어 정도로 계산됩니다.
R-Car H2의 시스템 정보를 보면 옥타 코어로 표기되는데 HMP 동작을 의미합니다.
(링크 : https://gfxbench.com/device.jsp?benchmark=gfx40&os=Android&api=gl&D=Renesas+Lager&testgroup=info)
시스템 정보에 나온 1.4GHz를 리틀코어 클럭으로 생각하면 Cortex-A7 1.4GHz 쿼드코어 성능을 계산하면 10640 DMIPS
역시 무시할 수 없는 수준.
그런데도 A15 성능만 표기했다는거지요.
르네사스의 성능 발표는 빅코어 성능만 나온다는거지요.
HMP든 아니든.
이러면 R-Car H3도 실제 HMP 동작이 아닌가하는 가능성이 생기는데, 아무래도 시스템 정보와 벤치마크까지 나온 상태에서 바뀔 가능성이 낮아보이는게 사실입니다.

의문은 R-Car H2에서 Cortex-A15/A7 구성의 HMP를 사용했음에도 왜 다시 쿼드코어로 돌렸는가.
스루풋(throughput)뿐만 로우 레이턴시(low latency)도 중시한다.라는 부분에 이유일지도 모르겠습니다.
반응시간이라는 측면에서보면 HMP보다는 클러스터 마이그레이션이 더 적합할 것 같고,
그렇다면 IKS보다는 클러스터 마이그레이션일 가능성이 높을듯 합니다.
테그라X1이 왜 클러스터 마이그레이션으로 들어갔는지에 대한 해답이 이걸지도 모르겠습니다.
테그라X1은 애초에 타겟이 모바일이 아닌 차량용 플랫폼이었던듯.
메모리 대역폭은 50GB/s 로 나오는데,
발표한 사양 LPDDR4-3200, 32bit x4 의 대역폭은 51.2GB/s가 됩니다.
구체적인 수치보다는 적당히 표기한듯.
- GPU : GFX벤치

GX6650을 썼습니다.
같은 아키텍처인 GX6540, GX6850을 쓴 애플 A8, A8X와 비교가 가능합니다.
|
AP |
GPU |
Texel Fillrate |
Texturing |
Texel |
CLK FREQ |
추정 클럭 |
ALU2 |
Manhattan |
T-Rex |
|
A8 |
GX6450 |
3807 |
3248 |
8 |
473.63 |
475 |
30.9 |
20.5 |
46.3 |
|
A8X |
GX6850 |
7607 |
6563 |
16 |
475.38 |
475 |
66.4 |
39.6 |
73.4 |
|
R-Car H3 |
GX6650 |
|
10739 |
12 |
894.92 |
900 |
87.9 |
33.6 |
63.7 |
보통 최신 버전인 텍스처링보다 예전 버전인 텍셀 필레이트에서 결과가 더 높게 나옵니다.
그런데도 900MHz로 계산될 정도로 높은 결과가 나왔습니다.
비율로 보면 1.0~1.1GHz 정도로 높여볼 수도 있습니다. 근거는 적지만요.
벤치마크 결과로 R-Car H3 클럭을 계산해보지요.
A8X 기준으로 계산하면,
ALU2 : 838MHz
맨해튼 : 537MHz
티렉스 : 550MHz
A8 기준으로 계산하면,
ALU2 : 900MHz
맨해튼 : 519MHz
티렉스 : 436MHz
로우레벨 결과와 하이레벨 결과 차이가 크지요.
ALU2, 텍셀 결과를 보면 900MHz 인데, 맨해튼, 티렉스 결과를 보면 잘해야 550MHz 수준입니다.
700MHz 라는 발표 사양하고 얼추 맞지요.
(OpenGL ES3.2 드라이버의 문제일지도 모르겠습니다.)
대충 계산하면, 성능 게인이 20SoC -> 16FF 에서 +39%, 20SoC -> 16FF+ 에서 +60%
(링크 : 삼성, TSMC 공정 비교. (2016.01.18))
모바일용이 아니니 A8X급 전력이 가능하다고 잡고, 클러스터 수 차이만큼 추가 전력이 가능하다고 가정해서 4/3 만큼 추가 클럭 상승이 가능하다고 보면,
20SoC -> 16FF : 475 x4/3 x1.39 = 880MHz
20SoC -> 16FF+ : 475 x4/3 x1.60 = 1013MHz
사실 700MHz 이상의 클럭일 가능성이 있는건 르네사스가 발표한 성능치때문.
단정밀도(FP32) 460GFLOPS, 배정밀도(FP64) 290GFLOPS 입니다.
PowerVR 6XT는 기존 정보대로면 FP64 지원에 대한 얘기가 없는데 여기서는 FP64 연산성능 얘기가 나왔단 말입니다.
(링크 : 이매지네이션 PowerVR 시리즈6 코어 구성. (Imagination, Rogue))
PowerVR 7XT에서도 FP64는 옵션으로 지원입니다.
(링크 : 이매지네이션 PowerVR 시리즈7 발표. (Imagination PowerVR serise7) (update 2014.11.21))
내용보면 R-Car H2가 FP64는 지원하고 FP32 지원하지 않다고, H3에서부터 FP32도 지원한다는 식으로 적혀있습니다.
뭔가 좀 이상한데 굳이 이해하자면 API 지원 문제로 실제 활용이 안 되든가 했나 봅니다.
G6400으로 FP64 기준 170 GFLOPS면 1.2GHz 정도로 계산됩니다. 너무 높지요.
일단 FP32 기준으로보면 GX6650이면 384 GFLOPS/GHz 입니다.
SFU(Special Function Unit)가 USC마다 하나씩 있어서 1FLOPS/cycle이 추가되는데 이것까지 포함하면 480 GFLOPS/GHz가 됩니다.
FP64 성능이 FP32 성능의 절반이라고 잡으면 192 GFLOPS/GHz 이고, SFU가 FP64까지 지원한다고 보고 포함시키면 240 GFLOPS/GHz가 됩니다.
이걸로 FP32 460GFLOPS, FP64 290GFLOPS가 되는 클럭을 계산하면,
FP32는 1.2GHz 혹은 960MHz가 되고, FP64는 1.5GHz 혹은 1.2GHz 가 됩니다.
1.2GHz가 공통적으로 나옵니다.
이 내용을 종합해보면,
FP32 성능은 SFU 미포함, FP64는 SFU 포함 성능이고 클럭은 1.2GHz로 계산됩니다.
발표치와 차이가 크지요.
FP32/64 성능이 아닌 FP16/32 일 가능성도 생각해볼 수 있는데, FP16 460GFLOPS로 계산해보면 600MHz로 나옵니다.
벤치마크 결과, 발표 성능들이 보여주는 클럭이 다 제각각인데,
가장 현실적인 해석은 클럭은 600MHz 정도이고, 발표 성능은 FP64/32가 아닌 FP32/16 이라는겁니다.
그렇다면 발표 내용도 기존에 FP16을 지원하지 않다고 이번부터 지원하게 됐다는 식으로 어느 정도 앞뒤가 맞게 되고,
클럭도 적당한 선에서 계산됩니다.
문제는 ALU2, 텍스처링 결과입니다.
ALU2 결과는 API 지원 등의 원인으로 FP16이나 SFU가 활용되면서 클럭대비 성능이 올라간게 아닌가 하는 식의 추측도 가능한데, 텍스처링은 정말 어떻게 해석할 방법이 없습니다.
확실한건 추가 정보가 나와봐야할듯 합니다.
- Appendix
그 외 관련 슬라이드입니다.








'스마트폰 > 기타업체 ETC' 카테고리의 다른 글
| 하이실리콘 Hi3660 그래픽 성능. (HiSilicon Hi3660) (11) | 2016.08.24 |
|---|---|
| LG 뉴클런2 추정 유출 벤치 분석. (LG Nuclun 2 ?) (12) | 2016.07.18 |
| LG 뉴클런 후속작 추정 찌라시/프로토 타입 긱벤치3 결과 분석. (LG Nuclun) (33) | 2016.01.08 |
| 하이실리콘 기린950 GFX벤치 분석. (HiSilicon Kirin 950, Mali-T880) (update 2016.01.07) (22) | 2016.01.07 |
| 하이실리콘 기린950 CPU 사양/성능. (HiSilicon Kirin 950) (update 2016.01.07) (26) | 2016.01.07 |



댓글