- 시작하기 전에...
전에 TSMC 의 공정으로 포스팅을 한 적이 있는데,
(TSMC 28nm 공정.)
이런 리플이 달렸습니다.

하아......
사실 반도체 공정에 대한건 (블로그의 정체성을 생각하면) 한번쯤 다뤄야하는 내용인데, 솔직히 너무 어렵습니다.
수박 겉핥기로 설명되거나, 비전공자는 뭔 소린지도 모르는 얘기만 하다가 끝나거나, 둘 중 하나가 될 가능성이 높으니까요.
실리콘의 분자구조 얘기부터 들어가야하는데 그런걸 비전공자에게 이해시키는건 무리가 있지요.
제일 문제는 제가 잘 모른다는 것.;;
대학원 과정쯤 되어야 뭔가 현실과 접점이 보이지, 학부 수준에서는 이상적인 모델을 놓고해서 설명에 큰 도움이 안 됩니다. (제가 다니는 학교만 그런걸지도 모르겠네요. 서울대는 학부 과정에서 cpu 설계 배우는데 너희는 논리회로도 모르냐고 타박하는 교수님도 계시니...)
저 두가지 이유로 대부분의 설명은 풀노드, 하프노드 개념을 중심으로 간단하게 하고 넘어가겠습니다.
- 반도체
(흔히 반도체라하면 집적회로를 얘기합니다만, 원래는 도체, 유전체같은 물질을 말하는 것입니다.
여기서는 집적회로 개념을 대표하는 단어로 사용했습니다.)
공정을 이해하려면 일단 반도체의 구조에 대해 알아야합니다.
그리고 반도체는 기본적으로 트랜지스터의 집적체입니다.
반도체의 구조를 알기위해서는 기본적으로 트랜지스터의 구조를 알아야되는거지요.
트랜지스터에는 대표적으로 MOSFET, BJT 등이 있는데 현재 대세는 단연 MOSFET 입니다.

(MOS의 기본구조)
MOSFET 은 Metal Oxide Semiconductor Field-Effect Transistor 의 약자입니다.
왜 MOS 냐...
위에서부터 Metal(polysilicon) Oxide(SiO2) Semiconductor(doped Si) 순으로 배치되어있기때문.
Metal 부분을 Gate 라고 부릅니다.
동작원리를 간단히 설명하면,
게이트에 특정크기 이상의 전압이 걸리면, 소스와 드레인 사이에 채널이 형성되고, 소스와 드레인의 전압 차이에 의해 채널을 통해 전류가 흐르는 구조입니다.
(자세한건, Solid State Semiconductor 책들이 많으니 참고하세요.)
흔히 말하는 32nm, 45nm 공정 그럴때 저 수치들은 게이트의 길이를 말하는겁니다.
- 풀노드와 하프노드
기본적으로 풀노드는 ITRS 에서 규정하는 노드(게이트 길이)를 말합니다.
그리고 이전 세대 대비 70%로 감소된 노드를 풀노드라고 합니다.
하프노드는 풀노드 사이의 노드를 말합니다.
풀노드에서 다음 풀노드로 이전되는걸 한 세대로 봅니다.
왜 하필 70%냐?
(절대적인 수치는 아니지만) 트랜지스터의 스케일이 0.7배가 되면, 칩 면적은 0.5배가 됩니다.
(가로 x 세로 = 0.7 x 0.7 = 0.5)
동일면적의 칩이라면 집적도가 두 배가 되는거지요.
같은 면적에 두 배의 트랜지스터가 집적되는겁니다.
인텔의 경우를 보면,
10 µm
3 µm
1.5 µm
1 µm
800 nm
600 nm
350 nm
250 nm
180 nm
130 nm
90 nm
65 nm
45 nm
32 nm
22 nm
TSMC는
110 nm
90 nm
80 nm
65 nm
55 nm
40 nm
28 nm
인텔은 풀노드에 충실하게 공정을 옮겨가고 있는데, 이는 인텔의 전략인 틱-톡(Tick-Tock)과 관계가 있습니다.
틱에서는 이전 아키텍처에서 공정을 개선하고,
톡에서는 이전과 동일한 공정에서 새로운 아키텍처를 도입하는 식으로,
틱 - 톡 - 틱 - 톡 이 반복되는겁니다.
안정적인 공정 이전과 아키텍처 개선을 위한 방법으로, 이 때문에 인텔은 2년마다 공정이 풀노드 이전됩니다.
TSMC는 풀노드와 하프노드가 혼합되어왔습니다.
65nm 까지는 90nm 65nm 가 풀노드였고, 80nm 55nm 가 하프노드가 되었는데,
40nm 부터 그게 깨지게됩니다.
풀노드로의 공정 이전은 공정 특성이 크게 변해서 같은 칩이라도 완전히 새로운 설계가 필요합니다.
그에 비해 하프노드로의 공정 이전은 그 특성에서 큰 변화가 없습니다.
단순히 광학적인 축소로 달성할 수 있는 수준입니다.
풀노드 이전에 비해 난이도가 더 낮은겁니다.
(물론 풀노드에 비해 공정 축소 효과가 낮습니다.)
어쨌건 공정 축소 효과를 볼 수 있는데 반해, 그 난이도는 낮기때문에 하프노드를 선택해왔습니다.
그 결과 나온 것이 80nm, 55nm 였습니다.
하지만 55nm 이후 그게 쉽지가 않게 되었습니다.
45nm 가 아닌 40nm 를 선택하는데, 이유는 정확히는 모르겠습니다.
파운드리로서 마케팅을 위해서 45nm 이하를 목표로 한 것인지...
하여간 55nm 에서 풀노드로 공정 이전해서 40nm 를 목표로 했습니다.
그런데 알려졌다시피 40nm 공정 이전에서 굉장히 애를 먹었습니다.
이후 계획을 봐도 28nm 20nm 로 이어지는데, 모두 풀노드이지요.
TSMC도 하프노드를 포기하고, 풀노드만을 선택한 것이지요.
수치적으로는 하프노드지만, TSMC 의 공정 이전을 보면 55nm 40nm 28nm 를 선택하고 마치 풀노드처럼 공정을 이전합니다.
이걸놓고 TSMC가 하프노드를 선택한다고 말하기에는 무리가 있습니다.
- 공정을 줄이려는 이유
반도체 산업은 기본적으로 대량생산을 바탕으로 합니다.
그리고 반도체는 원형의 실리콘 웨이퍼를 기반으로 만들어집니다.
즉, 하나의 웨이퍼에서 더 많은 칩을 생산할수록 수익이 높아지는겁니다.
가장 쉬운 방법은 웨이퍼의 크기를 늘리는겁니다.
지름 25mm에서 시작한 웨이퍼는 점점 커져서 현재는 300mm 에 이르고 있고, 450mm 를 준비하고 있지만 막대한 투자비용으로 인해 정체되고 있는 상태입니다.
앞서 말했듯이 풀노드 이전 한번이면 집적도가 두배가 올라갑니다.
동일 웨이퍼에서 두배의 같은 칩을 만들 수 있습니다.
하지만 실제로는 두배 이상이 가능합니다.
수율이라는게 있는데, 이건 한 웨이퍼에서 얻을 수 있는 최대 칩의 수 중에서 실제로 쓸 수 있는 칩의 수를 뜻합니다.
예시 이미지에서 빨간점은 웨이퍼에서 불량이 난 부분입니다.
칩에 불량부분이 있으면 그 부분은 쓸 수가 없습니다.
그리고 웨이퍼가 원형이기때문에 사각형의 칩(다이라고 부릅니다.)을 만들면 가장자리에 잘리는 칩들이 생깁니다.
설계부터 이런 부분이 최소화되도록 신경쓰지만 완전히 없애는건 불가능합니다.
한 웨이퍼에서 얻을 수 있는 최대 다이수를 계산할 때 이런 부분들은 제외합니다.(과거에 삼성에서 100%를 초과하는 수율을 달성했다는건 이런 부분까지 살렸기때문입니다.)
위의 이미지를 보면 알 수 있듯이 동일한 불량 포인트가 존재해도, 다이의 크기가 작아지면 수율이 올라갑니다. 거기에 보통은 폐기되는 가장자리의 영역도 감소합니다.
집적도 상승으로 인해 추가적으로 얻어지는 다이 이외의 저런 요소로 인해 추가적으로 다이를 더 얻을 수 있습니다.
-추가
위의 예시 이미지를 놓고 계산해보지요.
(이미지상 한단계마다 집적도가 4배씩 올라가는듯)
1. 불량, 가장자리 증가분 무시
28개 -> 112개 (4배) -> 448개 (4배)
로 얻을 수 있는 다이가 증가합니다.
2. 가장자리 증가분 반영, 불량 무시
28개 -> 136개 (4.85배) -> 658개 (4.83배)
원래보다 더 많은 다이를 얻을 수 있습니다.
3. 불량, 가장자리 증가분 반영
10개 -> 103개 (10.3배) -> 620개 (6.01배)
앞선 경우와 비교해서 비율이 대폭 증가합니다.
이 모든걸 반영하는게 수율이라는 수치입니다.
35.7% -> 75.7% -> 94.2% 로 증가하지요.
물론 불량의 경우는 저렇게 균일하게 발생하는 경우는 현실과 잘 안 맞습니다.
수율과 공정의 관계에 대한 이해를 위한 예시일뿐입니다.
- 문제점
하지만 공정을 개선하기위해서는 물리적으로 어려움이 많습니다.




이론적으로는 공정이 한 세대 바뀔때마다,
동작전압(게이트 전압)은 70%로 떨어지고,
소비전력은 동일 클럭에서 35%까지 떨어집니다.
하지만 이론치에 가까운 변화는 130nm를 기점으로 불가능해졌습니다.

가장 큰 이유는 누설전류가 증가하기때문입니다.
누설전류를 억제하기위해서는 게이트 전압이 높아져야하고, 결국 공정을 이전했음에도 동작 전압이 충분히 떨어지지 못하는 결과를 낳습니다.
그러면 결국 소비전력이 예상보다 떨어지지 못하게 됩니다.
공정이 줄었을 때, 소비전력이 충분히 줄어들지 못하는게 왜 문제인가?
이것은 전력밀도라는 측면에서 봐야합니다. 단위면적당 소비전력이지요.
전력밀도는 단위면적당 발열량이라고 봐도 무방합니다.
쿨링 솔루션이 해결할 수 있는 단위면적당 발열량은 한계가 분명합니다.
이 말은 전력밀도가 최소한 이전 세대와 동일한 정도로 억제되어야지, 이전 세대보다 커져버리면 곤란하다는 얘기입니다.
앞서 말했듯이 공정이 한세대 이전되면 집적도는 두배가 됩니다.
같은 면적에 두배의 트랜지스터가 집적된 겁니다.
만약 트랜지스터당 소비전력이 감소하지 않고 이전과 동일하다면 어떻게 될까요.
같은 면적에 두배의 트랜지스터가 집적되었으니, 전력밀도가 두배가 되어버립니다.
지나친 고열은 반도체의 정상적인 동작을 방해합니다.
결국 제대로 동작하지 않는다는 얘기지요.
130nm 이전까지는 공정이 한 세대 바뀔때마다,
동작전압(게이트 전압)은 70%로 떨어지고,
소비전력은 동일 클럭에서 35%까지 떨어지게되는데,
여기서 클럭을 40% 증가시키면, 전력밀도가 동일해집니다.
(집적도가 두배이기때문에.)
그런데 130nm 이후로는 이런 식의 성능향상이 불가능해졌습니다.
결국 제한적인 클럭상승에 만족해야하는 상황이 된 것이지요.
이런 문제를 해결하기위해서 나타난 것들이,
HKMG (High-K Metal Gate) 같은 새로운 소재의 도입과, SOI, Tri-Gate 같은 구조적인 변화입니다.
(하지만 이것도 한계가 보이는듯합니다. 과거와 같은 극적인 변화는 힘들듯.)
- 그럼에도 필요한 공정 이전
공정 이전이 필요한 가장 큰 이유는 수익성이지만, 성능이라는 측면을 무시할 수 없습니다.
cpu는 주로 클럭을 상승시키는 방식으로 성능을 향상시키지만,
gpu는 클럭 상승보다는 더 많은 쉐이더프로세서(=트랜지스터)를 집적시키는 방식으로 성능을 향상시켜왔습니다.
그 결과, gpu칩은 계속적으로 거대해져왔습니다.
인텔의 6코어 cpu의 트랜지스터 수가 11.7억개인데 반해,
엔비디아의 GF110(GTX500 탑재)은 30억개, AMD의 Cayman 코어(HD6900 탑재)는 26.4억개입니다.
공정 이전없이 트랜지스터 수만 늘리면 칩의 크기가 거대화되는데, 앞서 보았듯이 거대한 칩은 웨이퍼당 생산량이 적을뿐 아니라 수율도 낮아서 가격이 상승되게됩니다.
현실적으로 판매할 수 있는 가격과 시장에 공급할 수 있는 충분한 물량을 갖추려면 칩의 크기는 적당한 선에서 제한될 수 밖에 없습니다.
결국 성능을 올리려면 공정 이전 밖에 답이 없습니다.
성능을 높이려면 몸집을 키울 수 밖에 없는 것이 반도체이기때문에 반도체 제조에서 공정 이전은, 힘들지만 할 수밖에 없는 것인겁니다.
p.s 굉장히 생략을 하면서 설명했네요. 궁금한 것이나 틀린 것 있으면 질문이나 지적해주세요.
- 2012.02.25 수율 계산 수정.
'반도체 강좌' 카테고리의 다른 글
| 낸드플래시(Nand Flash)에 대해 알아봅시다. (113) | 2013.04.10 |
|---|---|
| 반도체 강좌. (4) Nonequilibrium Excess Carriers (48) | 2013.01.05 |
| 반도체 강좌. (3) 에너지 밴드 차원에서의 반도체 해석. (102) | 2012.08.15 |
| 반도체 강좌. (2) 반도체와 캐리어. (86) | 2012.06.24 |
| 반도체 강좌. (1) 실리콘 결정구조와 에너지 밴드. (60) | 2012.06.17 |
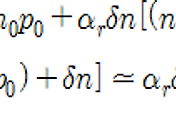


댓글