- 컴퓨텍스 2016에서 ARM의 신규 GPU 아키텍처, 비프로스트(Bifrost)가 발표됐습니다.
유출? 공개? 로드맵으로 보아 Mimir(미미르)에 해당하는듯 합니다.

2016년 디바이스 대비 성능 1.5배
말리써서 플래그쉽급 성능 만드는데는 삼성 밖에 없지요.
아무래도 엑시노스8890(Mali-T880MP12)가 기준일까요?


네이밍이 바뀌었습니다.
G를 붙인건 Cortex 계열과 함께 네이밍의 통일성을 위해서 인 것 같기도 하네요.
(GPU니까 G?)
아래에서 언급되는 Full coherency 측면에서보면 기능적으로 CPU와 같은 비중을 부여하는 느낌도 있습니다.
우트가르드 - 미드가르드 - 비프로스트 로 이어지는 아키텍처 이름때문에 차기 아키텍처는 아스가르드(Asgard)가 아닌가 하는 추측도 해볼 수 있습니다.
미드가르드(인간계)에서 비프로스트(다리)를 건너서 아스가르드(아스 신계)로 이어지니까요.

이런 특징으로 성능이 올라갔다는데 사실 가장 중요한건 연산유닛이 벡터에서 스칼라 방식으로 바뀌었다는겁니다.

GPU 구성을 보면 쉐이더 코어가 최대 32개까지 가능합니다.
16코어까지 가능했던 T880에 비해 2배로 늘었습니다.
거꾸로 보면 1코어당 성능이 그렇게 많이 오르지 않았다는 반증도 됩니다.
경쟁 아키텍처와 성능을 맞추려면 코어를 저 정도로 늘려야된다는 얘기니까요.
이건 CPU 아키텍처도 마찬가지지만 하이엔드~로우엔드까지, 최소한 하이엔드~미드레인지까지 단일 아키텍처로 커버해야하는 ARM 레퍼런스 IP의 태생적 한계입니다.
각 성능 영역에 맞는 최적의 아키텍처를 모두 만들어서 공급할 수는 없는 노릇이니, 코어 개수 조절로 성능을 조절하게 하는 수 밖에 없지요.
그러다보니 가장 문제가 되는게 플래그쉽급 성능에 뽑아내는데 한계가 있습니다.
CPU로 치면 싱글코어 성능에 한계가 있는 것과 같은 상황.

쉐이더 코어 1개는 위와 같이 3개의 Execution engine으로 구성되어 있습니다.
하나의 엔진은 32bit ALU 4개로 구성되어 있습니다.
아래 슬라이드에 나오는 Lane이 1ALU 입니다.

SIMD(벡터) 구조에서는 위와 같은 스레드가 오면 레인 하나가 놀고, 최종적으로 처리하는데 4사이클이 필요합니다.

스칼라 구조에서는 이를 재배치해서 가용 자원을 최대한 활용하게 합니다.
예시에서는 그 결과 기존 방식에서 4사이클이 필요했던 작업이 3사이클만에 처리됐지요.
스칼라 방식으로 넘어온건 사실 많이 늦은겁니다.
이매지네이션, 엔비디아 등등 한 성능한다는 아키텍처는 이미 모두 스칼라 방식을 채택하고 있습니다.
(무조건 좋은 전성비로 이어지는건 아니지만요.)

1ALU는 위와 같이 1FMA + 1ADD/SF로 구성되어 있습니다. (32bit 기준)
1 Execution engine = 4 ALU 입니다.
일반적으로 연산유닛 단위가 32bit x4 로 구성되었으니 당연하다면 당연한 구성.

이 차트로만 본다면 1ALU는 최대 FP32 3op/cycle이 가능하겠네요.
미드가르드 아키텍처가 보기와 다르게 17op/cycle이 가능했던 것처럼, 비프로스트도 실제 더 높은 연산성능이 가능할 수 있으니 정확한 정보가 나오기를 기다려봐야겠습니다.
어쨌든 이 자료만 봐서 1ALU가 FP32 3op/cycle가 가능하다고 보면,
1 Execution engine = 4 ALU 이니 최대 FP32 12op/cycle이고,
1쉐이더 코어 = 3 Execution engine = 12 ALU 이니 최대 FP32 36op/cycle
T880MP1이 FP32 기준 12개였으니 기본적으로 연산유닛 규모는 차이가 없어보입니다.
물론 수치로 보이지 않는 차이는 자세한 정보가 필요하겠고요.
T880MP1 연산성능은 51op/cycle 입니다.
미드가르드의 연산성능은 이 연산, 저 연산 죄다 끌어모아서 만든 수치라서 실제 성능과 관련된 연산성능은 그렇게 높지 않습니다.
이전에 끄적였던 분석이 맞다면 실제 유의미한 연산성능은 27op/cycle 수준입니다.
(링크 : Adreno330 vs Mali-T628 GFXBench Manhattan 성능 차이 분석.)
G71의 1코어의 연산성능이 36op/cycle이라 하더라도 실제 유의미한 연산성능은 G71이 더 높을 가능성이 높다고 봅니다. (일단 수치상으로는 +33%네요.)

최대 32코어라는 앞서 얘기했고 이미지에서 나오지만 VR 타겟이라고 합니다.
- 성능 분석

같은 공정, 같은 조건에서 T880 대비
에너지 효율 +20%
성능 밀도 +40%
에너지 효율 +20%라는건 결국 동일소비전력에서 성능 +20%라는 겁니다.
전성비 +20%와도 같은 얘기.
그 성능이 기준이 뭐냐는게 불확실하고요.

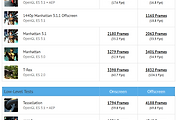
GFX벤치 맨해튼 3.1 오프스크린 기준 성능 비교인데,
맨 밑의 Mali-T880MP12는 누가봐도 엑시노스8890 입니다.
그래프를 비교해보면 Mali-G71MP16은 엑시노스8890 성능의 1.8배입니다.
이미지를 보면 같은 스마트폰입니다.
이건 TDP가 같다는 의미입니다.
이 차트에서 G71MP16과 T880MP12의 소비전력이 같다고 봐야합니다.
그런데 앞서 G71의 전성비가 T880의 1.2배라고 했지요.
전성비 1.2배의 기준이 맨해튼3.1이 아니라 하더라도 1.2와 1.8의 차이는 너무 큽니다.
이 차트에서의 비교 기준과 전성비 1.2배에서의 비교 기준이 다르다는 의미입니다.
전성비 1.2배의 기준은 동일 공정, 동일 조건이었지요.
여기서 더 이상 진척이 없으니 전성비 1.2배의 기준이 맨해튼3.1 이라는 가정을 하겠습니다.
성능차 1.8배에서 전성비 1.2배를 빼면 1.5배가 됩니다.
아키텍처에 의한 성능 차이를 무시하고 사양만 비교한다면 G71MP16과 T880MP12의 차이가 1.5배라는 겁니다.
사양이라면 MP수와 클럭이 거의 전부라고 봐도 되겠지요.
MP수를 맞춰보면 G71과 T880의 사양 차이 = 클럭 차이는 1.5x12/16 = 1.125배가 됩니다.
갤럭시S7 기준으로 보면 Mali-T880MP12 클럭은 맨해튼3.1 기준 650MHz 입니다.
(링크 : 엑시노스8890 GFX벤치 분석. (갤럭시S7, Mali-T880))
이것의 1.125배라면 731MHz가 되네요. 보통 쓰는 숫자로하면 733MHz
Mali-G71MP16 733MHz ?
- 10nm 엑시노스?
앞서 언급했지만 말리로 플래그쉽 제품 만드는데는 삼성 밖에 없습니다.
G71MP16이 차기 엑시노스의 사양일거라는 추측은 쉽게 할 수 있습니다.
그런데 추정되는 사양이 G71MP16 733MHz 입니다.
T880MP12 650MHz로 거의 14LPP 공정의 최대치를 썼다고 봐도 무방한 상황에서 그 이상의 사양이 나왔습니다.
이건 자연스럽게 다음 공정이 적용되었다고 봐야합니다.
면적 측면에서보면 앞서 성능밀도 +40%, 전성비 +20% 라고 했습니다.
같은 전력 상태에서 성능이 1.2배이고, 성능밀도 1.4배를 적용하면 면적은 1.2/1.4 = 0.86배가 됩니다.
MP수 증가로 단순 계산으로 MP12 -> MP16이니 +33%입니다.
면적은 1.33 x0.86 = 1.14, +14%로 나오네요.
(이것도 성능밀도 기준이 맨해튼3.1 이라는 가정 하에서 입니다.)
same condition이라는게 구체적으로 어떤건지 알 수 없기때문에 실제 면적 증가는 저 값과 다를 수 있습니다.
클럭 측면만보면 클럭이 13% 올라갔는데 보통 MP수가 늘어나면 클럭은 떨어지지요.
ARM의 정보를 보면 TSMC 16nm FinFET 공정에서 T880, G71 모두 850MHz라고 표기하고 있습니다.
두 아키텍처의 클럭 특성은 근본적으로 차이가 없거나 거의 없는 것으로 보입니다.
소비전력 제한만 없다면 공정 스피드게인 특성에 따른 최대 클럭은 같다고 볼 수 있습니다.
엑시노스8890의 GPU클럭이 소비제한에 걸려서 더 올라가지 못 했을 가능성이 큰 상황에서 G71MP16의 클럭이 올라갔다는건 무언가 소비전력을 줄이는 요소가 있었음을 의미합니다.
더 말할 것도 공정 차이일겁니다.
+14%의 면적 증가를 상쇄하고, 13%의 추가 클럭 상승을 가능하게하려면 14LPP -> 14? 같은 동일 노드 내 공정 변경으로는 안 될겁니다. (특히 면적이.)
10nm 공정이 적용되었다는 결론을 낼 수 밖에 없습니다.
그렇다면 10LPE이냐 10LPP이냐가 남는데 최근 삼성의 발표를 보면
14LPP -> 10LPP에서 성능 +20%, 면적 -32%
14LPP -> 10LPE에서 성능 +10%, 면적 -32%
클럭 상승치나 벌써 테스트할 수 있는 샘플이 있는 점을 감안하면 10LPE 공정으로 보는게 타당합니다.
단순계산이지만 10nm 공정에서 면적 -32%라면 14LPP 기준 현재 면적보다 +47%의 구성이 가능합니다.
위에서 계산한 T880MP12 -> G71MP16 에서의 면적 증가가 +14%이니 1.47/1.14 = 1.29, +29% 여유가 더 있네요.
(16 x1.29 = 20.6, MP20까지 가능?)
- 정리
Mali-G71
Bifrost 아키텍처
스칼라 방식
1쉐이더 코어 = 3 Execution engine = 12 ALU
1ALU = 32bit FMA + 32bit ADD/SF
1쉐이더코어 최대 FP32 36op/cycle 추정
같은 공정, 같은 조건에서 T880 대비
에너지 효율 +20%
성능 밀도 +40%
성능비교의 Mali-G71MP16은 10LPE 공정 엑시노스 ?
'스마트폰 > mobile GPU' 카테고리의 다른 글
| 이매지네이션 PowerVR Furian 아키텍처 발표. (Imagination PowerVR Furian) (22) | 2017.03.09 |
|---|---|
| ARM Mali-G71 성능 분석. (하이실리콘 기린960) (2) | 2016.12.04 |
| ARM Mali-T830 GFX벤치 결과 분석. (AmLogic S912) (5) | 2015.11.18 |
| MT6755 (Helio P10)으로 보는 Mali-T860 성능 (update 2015.11.18) (11) | 2015.10.29 |
| ARM Mali-T720 그래픽 성능 연구. (25) | 2015.05.06 |


댓글