Linpack(린팩) 안드로이드 버전은 린팩 기반으로 개발한 자바 버전이며, 안드로이드 스마트폰의 부동소수점 연산 성능을 측정합니다.
계산 밀집형 스레드 Ax=b를 통해 계산 속도를 알아냅니다.
안드로이드 Dalvik 가상 머신에서 부동소수점 연산 테스트를 합니다.
현재 스마트폰 시장을 독점하고 있는 ARM 기반으로 아키텍처는 다음 정도입니다.
Cortex-A8
Cortex-A9
퀄컴의 Scorpion
같은 아키텍처라도 제조사에 따라 성능에 차이가 있습니다.
여기저기서 찾아본 자료는 다음 정도입니다.
컴퓨터 구조에 대해 구체적으로 아는바가 없기때문에 각 아키텍처의 차이에 따른 성능 차이의 원인은 정확히 모르겠네요.
(작은 사진은 클릭하면 커짐.)
http://www.anandtech.com/show/4940/qualcomm-new-snapdragon-s4-msm8960-krait-architecture/1
http://www.anandtech.com/show/4551/motorola-droid-3-review-third-times-a-charm/10
http://pc.watch.impress.co.jp/docs/column/kaigai/20111028_487030.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20111130_494357.html

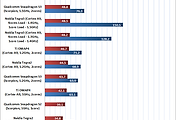
Scorpion과 Cortex-A9 의 비교.
부동소수점 연산 유닛의 차이로 성능차이가 있다는 퀄컴의 주장인데, (뒤에 나오지만) 실제로는 동클럭에서 특별한 차이는 보이지 않습니다.




(좌 : Cortex-A7 코어 다이어그램, 우 : Cortex-A8 코어 다이어그램)


(좌 : Cortex-A9 코어 다이어그램, 우 : Cortex-A15 코어 다이어그램)

OMAP 4: Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3
Exynos: Features : swp half thumb fastmult vfp edsp neon vfpv3
Tegra 2: Features : swp half thumb fastmult vfp edsp vfpv3 vfpv3d16
MSM8260: Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3
OMAP 3: Features : swp half thumb fastmult vfp edsp neon vfpv3

린팩 벤치 자료를 모으는데 사용된 링크가 21개.
벤치마크 된 제품이 53종. 결과가 68개.
중간에 OMAP3, 허밍버드의 결과도 있었지만, 결과 간 편차가 심하고 결과도 몇개 없어서 제외.

1) 중간에 테그라3의 멀티스레드 결과가 높게 나온건 혼자 쿼드코어이기때문.
2) 스냅드래곤은 사실상 세대별로 큰 차이가 없어서, 하나도 통합해도 무리가 없는 수준.
3) 더 높은 클럭으로도 Cortex-A9 기반에 밀리는 스냅드래곤.

위의 결과를 1GHz 기준으로 결과를 정규화 시킨 것이다.
1) 테그라2의 부진
NEON이 제외되었기때문이 아닌가 추측.
Cortex-A9에서 NEON이 빠지면 사실상 부동소수점연산 유닛이 빠지는 것과 같아서, 소프트웨어적으로 처리해야하는데, 듣기로는 엔비디아에서는 이를 대체하는 다른 방식을 사용했다고 한다.
문제는 대부분의 어플 개발자(사)들이 표준에서 벗어나는 이 방식을 따르지 않았다는 것.
테그라2의 동영상 호환성 문제도 그 때문이라고 한다.
물론 어플 개발자(사)를 탓할 부분은 아니다.
굳이 책임을 묻겠다면 다이사이즈 줄이겠다고 표준을 따르지 않는 엔비디아에게 물어야할 것이다.
2) 엑시노스의 선전
스냅드래곤이나 테그라보다 25% 높고, OMAP4 와 비교해도 10% 높다.
아키텍처 면에서 아는게 없는 본인의 입장에서는 미스테리하기까지 한 성능 차이.
3) 최적화의 영향
OS 버전의 변경으로도 결과가 제법 차이가 나는 경우가 있다.
그 때문인지 테그라2의 경우 좀 심하게 떨어지는 결과가 있는데, 이걸 제외해도 평균이 테그라3와 비슷하다.
-
스마트폰 AP 성능 비교시에 보통 사용하는 것이 클럭(1MHz)당 명령어 처리수 (Dmips = Dhrystone Million Instructions Per Second) 입니다.
일종의 정수연산 성능인데, Antutu 같은 어플로 벤치마크해보면 ARM이나 퀄컴의 발표수치대로 나오는 편입니다.
AMD는 일상 작업의 80%가 정수연산이라고 하더군요.
실성능을 판단하는데 정수연산성능을 따지는게 더 적당하다는 얘기겠지요.
(그걸 근거로 두 코어가 부동소수점 연산 유닛을 공유하는 모듈방식을 사용한 불도저가 딱히 좋은 결과를 내지 못하는 걸 봐서는 신뢰도가 의심이 가긴 합니다만...)
부동소수점 연산에서도 비슷한 결과가 나오지 않을까하는 약간은 터무니없는 생각으로 시작해봤는데,
역시나 큰 관련이 없었네요.
Antutu 결과를 찾기가 힘든데, 어느 정도 자료가 모이면 이것도 정리해봐야겠습니다.
'성능비교 그래프 > 부동소수점 연산 (VFP)' 카테고리의 다른 글
| ARM 부동소수점 연산 성능 비교 v12.5 (4) | 2012.05.04 |
|---|---|
| ARM 부동소수점 연산 성능 비교 v12.4 (4) | 2012.04.05 |
| ARM 부동소수점 연산 성능 비교 v12.3 (2) | 2012.02.24 |
| ARM 부동소수점 연산 성능 비교. v12.2 (2) | 2012.02.01 |
| ARM 부동소수점 연산 성능 비교. v12.1 (32) | 2012.01.03 |



댓글