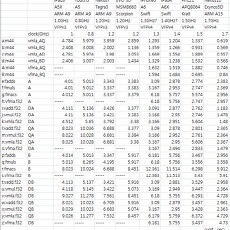
반응형 cortex-A93 ARM 기반 아키텍처별 부동소수점 연산성능. 올라온지 좀 된 자료인데 린팩보다 훨씬 더 정확한 것 같아서 올립니다. (http://wlog.flatlib.jp/item/1620) 원본의 내용을 다수 참고하고 있으며 일부 저의 해석이 들어갔습니다. 테스트 원본입니다. (물론 테스트 자료 여러 개 취합해서 정리한건 저...) 결과 단위는 초(sec) 입니다. 값이 작을수록 빠릅니다. 각 제품마다 클럭이 다르기때문에 1.0GHz 기준으로 정규화한 결과입니다. 이래야 제대로 된 비교가 되겠지요. - 공통내용 m44 : NEON을 사용한 4 x 4 매트릭스 연산. A : 파이프라인 최적화 없음, 인/아웃이 완전히 다른 레지스터. B : 4명령마다 인터리브(Interleave, 동시참조), 레이턴시가 커질 경우 A보다 스톨(stall)이 발생할 가능성 높음... 2013. 6. 5. AP 제조사별 Cortex-A9 다이 비교. 본 포스팅 이미지의 출처는 Chipworks, UBM Techinsight 입니다. http://www.ubmtechinsights.com/ http://www.chipworks.com/ ARM에서는 위와 같이 Cortex-A9 Floorplan을 제시하지만 제조사(설계사)에서 그대로 따르는 경우는 많지 않습니다. 자사 상황에 따라 변경하지요. 그래서 다이를 비교함으로써 설계를 어디서했는지 추정해볼 수 있습니다. 절대적인건 아니지만요. 이미지는 동일 축척이 아닙니다. - Nvidia Tegra2 TSMC 40nm, 49mm2 - TI OMAP4430 UMC 45nm, 68mm2 - TI OMAP4430 UMC 45nm, 68mm2 - Samsung Exynos4210 Samsung 45nm LP, 118.. 2012. 12. 26. 모바일 AP 둘러보기. (3) Cortex-A9 (1) 기起 : Cortex-A9 Cortex-A9 는 Cortex-A8 에서 많은 부분이 바뀌었습니다. 가장 큰 변화는 In-Order (순차실행)에서 Out-of-Order (비순차실행)으로 바뀐 것입니다. 무겁고 느린 명령어를 처리하게되면 병목으로 인해 체감성능이 크게 떨어지는 순차실행에 비해, 비순차실행은 실제 성능향상치보다 체감성능향상을 더 크게 느낄 수 있게 만드는 부분입니다. 멀티코어 지원도 중요한 변화입니다. 명령어처리능력(정수연산)은 2.5 Dmips/MHz 로 Cortex-A8 에 비해 25% 증가했으며, 부동소수점연산 유닛도 대폭 강화되어, 성능이 Cortex-A8 에 비해 3배 수준으로 증가합니다. 비로소 모든 면에서 스냅드래곤을 넘어서는 성능을 갖춘겁니다. (좀 오래걸렸지요?) (.. 2012. 1. 26. 이전 1 다음 반응형