- 인텔

인텔 TSMC N6, N3E 공정 사용.
내용으로 봐서 6nm는 베이스 다이(base die)로 보임.
N3B(N3이라고 불리던 초기 3nm 공정.)에서 N3E로 마이그레이션됐다는걸로 보아 초기에 N3으로 설계했다가 N3E로 변경한듯.
아래의 내용으로 보아 애로우 레이크 GPU 타일이 N3E 공정일 것으로 추측.

TSMC 3nm 공정 MDIO(Multi Die IO) IP
die간 통신 블록같고 SOC tile, GPU tile, IOE tile 중 TSMC 3nm 공정을 쓰는게 있다는 것.
현재로는 메테오 레이크(meteor lake)나 애로우 레이크(arrow lake)가 대상일 것으로 보이는데
메테오 레이크에는 3nm 공정이 안 들어가는 것으로 알려져있고, 애로우 레이크는 메테오 레이크의 SOC, IOE 타일을 활용한다고 알려져있음.
그렇다면 애로우 레이크 GPU 타일이 3nm 공정일거란 추론이 가능함.
- 삼성


커스텀 GPU
어느 정도 수준의 커스텀을 의미하는지는 불명.

구글 텐서 코드 S5P9845, S5P9865
같은 출처에 이전에는 S5E로 표기되어있었는데 수정되었음.
(파운드리 단신. (2022.12.05. 삼성, AMD, 엔비디아))
그동안 흐름상 S5P가 맞긴한데 이 쪽 소스도 틀린 정보 흘리는게 가능한 단계에 들어선게 아닌가 싶어서 판단에 좀 더 신중해져야할듯.

삼성 4nm 공정 Cortex-A78?
작업한 곳이 삼성이 아닌데다 4nm 공정, CA78(Hercules)가 직접적으로 연결돼있지 않아서 가능성이 다양함.
CA78이 4nm인지, 5nm인지 / CA78을 사용하게 엑시노스인지 다른 팹리스 업체 칩인지.
최근 미드레인지 엑시노스 사양으로 보아 4nm 공정 제품까지 CA78을 끌고갈 가능성은 충분히 있음.

8 SoC + 4HBM 구성 삼성 공정 제품?
실리콘 인터포저 적용한 패키징 제품인데 TSMC(1 SoC + 4HBM)은 엔비디아나 AMD 플래그십 GPU로 볼 수 있겠고, 구글(1 SoC + 2HBM)은 TPU V2가 같은 구성을 갖고 있음.
삼성 자체 제품이나 삼성 파운드리 이용한 고객사 제품까지 넓혀봐도 지금까지 공개된 것 중에서는 같은 사양의 제품이 없음.
(파운드리에서 주문받으려고 준비했다가 실패한건지, 아직 출시를 안 한건지?)
현재로는 IBM(Z, Power 시리즈) 차기 제품이고 구조적으로 크게 변경된게 아닐까 추측하는게 최선인듯.
AI, HPC, 슈퍼컴퓨터 쪽 전용칩에 HBM 적용하려는 움직임이 있다는 썰도 있으니.

삼성 3DIC 프로젝트.
용도는 불명.

삼성 3DIC 테스트 칩.
4nm, 5nm 공정 경력이 있는데 이것과 테스트 칩이 직접 연결되지는 않음.
3DIC 그러면 보통 SRAM, DRAM 적층이 거론되는데 모바일에서는 무조건 좋은게 아닌게 모바일 AP는 연결방식만 다를뿐 구조적으로 DRAM이 로직 위에 올라간 구조임.
거기에 (AMD V-Cache처럼) SRAM을 적층하려면 로직과 SRAM이 TSV로 적층되고 그 위에 DRAM이 패키징되는 형태가 예상 가능함.
둘 다 TSV를 통하는건 어려울듯한데 삼성이 최근 발표한 Saint에서도 SRAM, DRAM, 로직 적층을 각각 적용하지 동시 적용하는 예를 보여주지는 않았음.
그런데 (AMD 사례만봐도 알 수 있듯이) 이렇게되면 방열에 불리해져서 온도관리와 클럭 상승에 어려움이 있음.
(라이젠X3D 온도 높은게 확장된 L3 캐시 덕에 코어 유닛 활성화 빈도가 높아진게 원인이지 방열 측면에서 non 3D와 차이없다는 주장도 있는데, 이건 높이 맞추려고 코어 위에 올라간 structural silicon의 열전도도가 알루미늄급은 돼야 타당한 주장임.)
그렇다고 DRAM을 로직 위가 아닌 옆으로 옮기면 면적 감소는 커녕 오히려 최종적으로 증가하는게 돼서 메리트가 없음.
결국 모바일 제품에서 3DIC가 유효하려면 먼저 로직 전성비가 경쟁사와 대등한 수준은 돼야하고
(적층을 통한 SRAM 증가가 열세에 있는 로직의 성능, 전성비를 역전시켜줄 수 있는 일발역전의 치트키는 아니라는거.)
SRAM 적층으로 증가된 SRAM 용량에 의한 성능 증가를 까먹지 않도록 패키징 구조적으로 방열 성능을 최적화할 수 있을 것인가가 관건일듯.
- AMD

3nm 공정 캐시, 코어.
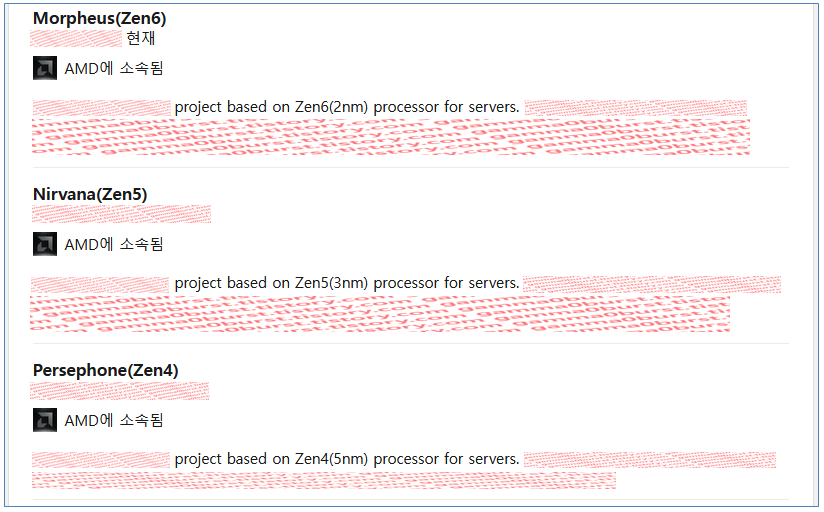
Zen5 코어 3nm 공정, 코드네임 Nirvana / Zen6 코어 2nm 공정, 코드네임 Morpheus
코드네임은 최종 제품이나 CCD가 아니라 코어 아키텍처의 코드네임.
사견으로는 서버 프로세서 공정으로 나왔으니 같은 CCD를 쓰는 데스크탑도 같은 공정일거라 보는데...
지금까지 루머로는 Zen5는 서버, 일부 APU(아마도 MI300같은거?)에 3nm고 데스크탑은 4nm 공정이라고 하는데, 원가 차원에서 서버, 데스크탑 모두 같은 CCD를 쓰는 AMD가 그 둘의 공정을 다르게 가져갈지 의문.
(일단 Zen4 제품 사례와 AMD 로드맵으로 보아 Zen5는 데스크탑/서버는 4nm, APU가 3nm일 것으로 예상했는데 아니었음.)
Zen5 계열에서 제품별로 4nm, 3nm 적용을 어떻게 가져갈지 가능성을 얘기해볼 수는 있는데 지금은 딱히 의미가 없을듯.

Zen5 X3D 제품 존재 확인.
Zen4에서 CCD는 5nm로 공정이 바뀌었는데 3D V-Cache는 이전과 같은 7nm임.
셀 라이브러리를 고밀도로 바꾸고 설계 최적화로 면적이 줄긴했는데 그래도 CCD 면적 감소는 못 따라가서 Zen3 때와 다르게 캐시 다이가 CCD의 L2 캐시 영역을 덮음.
Zen5 아키텍처 규모가 크게 늘어난다는 루머가 있어서 3nm로 공정이 바뀌어도 최종 CCD 면적이 엄청나게 줄지는 않겠지만 여전히 CCD당 8코어라는걸 봐서는 면적 축소는 피할 수 없어보이고, 3D V-Cache 공정 미세화가 없다면 코어 영역까지 덮게될 가능성이 높아서 이를 피하기 위해서라도 공정이 바뀌어야할텐데 어떨지?

4nm GPU
외장 GPU인지, 내장 GPU인지 불명.

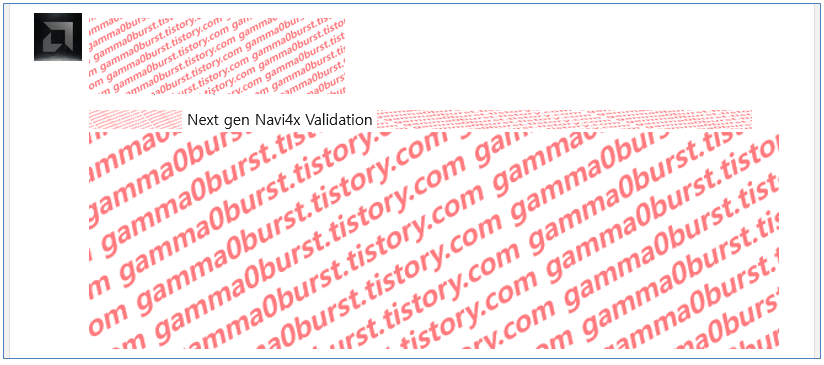
RDNA4(Navi4x) 작업 중.
- 퀄컴

누비아 CPU 모바일, 컴퓨트 프로세서 모두 적용.

누비아 CPU 탑재 데이터 센터용 SoC DDR5 대응.

스냅드래곤에 누비아 코어 탑재.
- 기타

애플 혹은 구글 제품 CPU N3E, N4 공정 사용.
구글 텐서는 삼성 4nm 사용까지는 확인됐으니 텐서에 N4 가능성은 낮음.
N4 적용 가능성은 애플, 구글의 텐서 외 제품 정도.
구글은 HPC용 자체 CPU 개발 정황이 있어서 이 쪽의 가능성도 있음.
N3E는 애플, 구글 모두 가능성 있음.
'단신 > 단신' 카테고리의 다른 글
| 팹리스, 파운드리 단신. (2023.05.16. 삼성, 인텔, 퀄컴) (2) | 2023.05.16 |
|---|---|
| 팹리스, 파운드리 단신. (2023.04.20. 인텔, 애플) (1) | 2023.04.20 |
| 팹리스, 파운드리 단신. (2023.03.25. 삼성, 비보, 애플) (2) | 2023.03.25 |
| 팹리스, 파운드리 단신. (2023.03.01. 퀄컴, 인텔, 삼성) (0) | 2023.03.01 |
| 파운드리 단신. (2023.02.10. 퀄컴, 메타) (1) | 2023.02.11 |




댓글